 Motivation: GPT-4V make mistakes on simple positioning problems
Motivation: GPT-4V make mistakes on simple positioning problems
Representative examples of GPT-4V failure cases. In both questions, GPT-4V correctly identifies all objects in question, but chooses the wrong answer because it fails to distinguish between either left and right (the left question) or up and down (the right question).

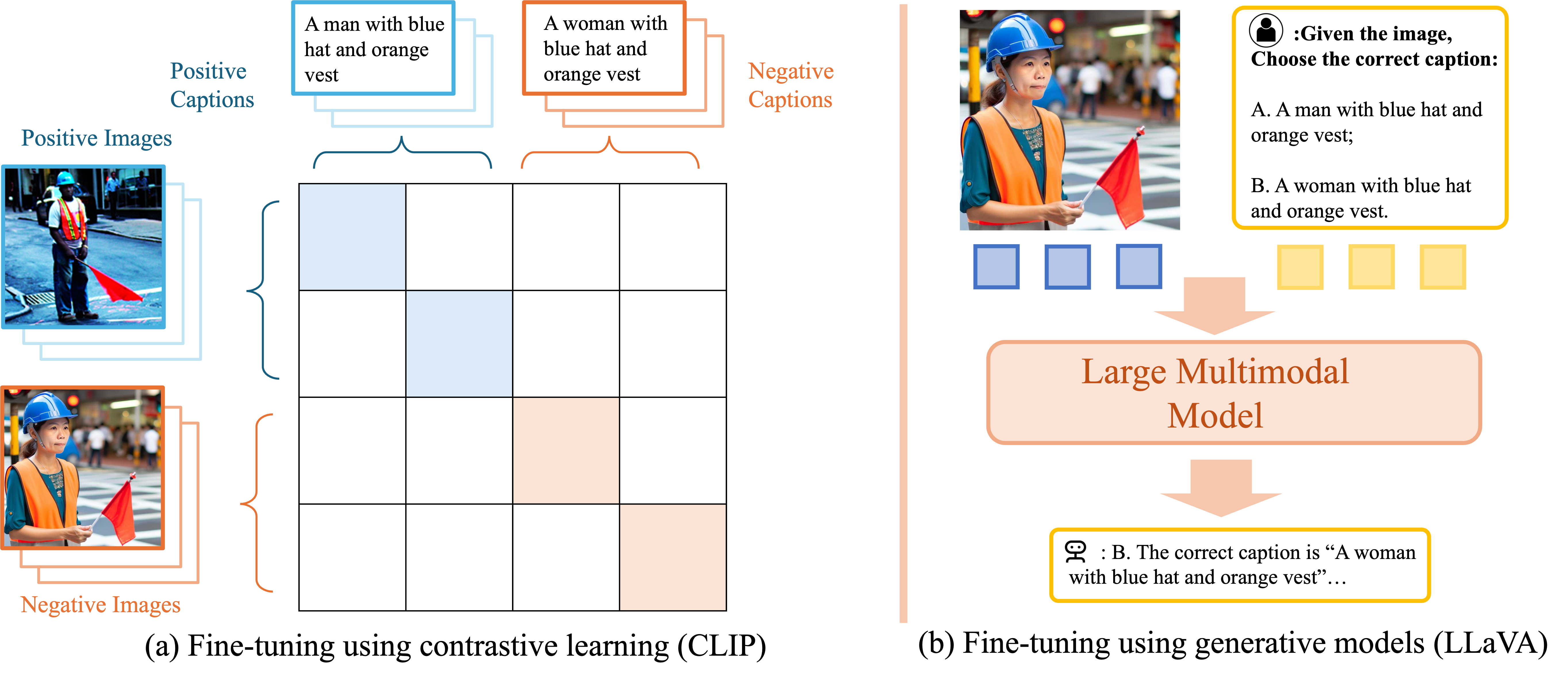
 The data curation pipeline of CounterCurate
The data curation pipeline of CounterCurate
Given a positive image-caption pair, we first generate the negative captions, based on which we generate the negative images using the most suitable approach. Specifically,
- Flickr30k-Positions: for left/right, we flip the positional keyword, and then conduct the horizontal flip for the image;
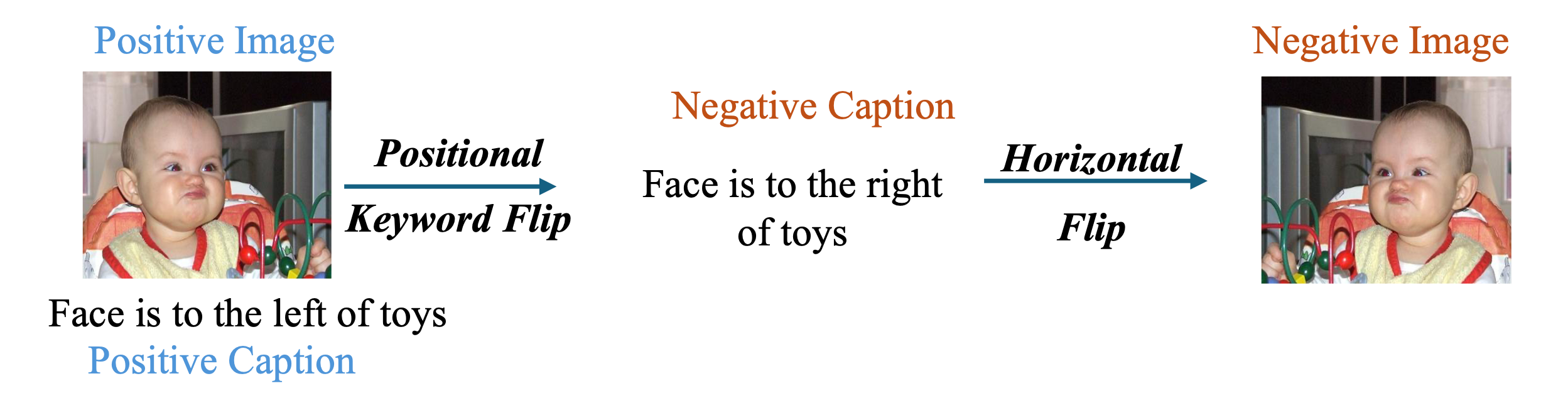
-
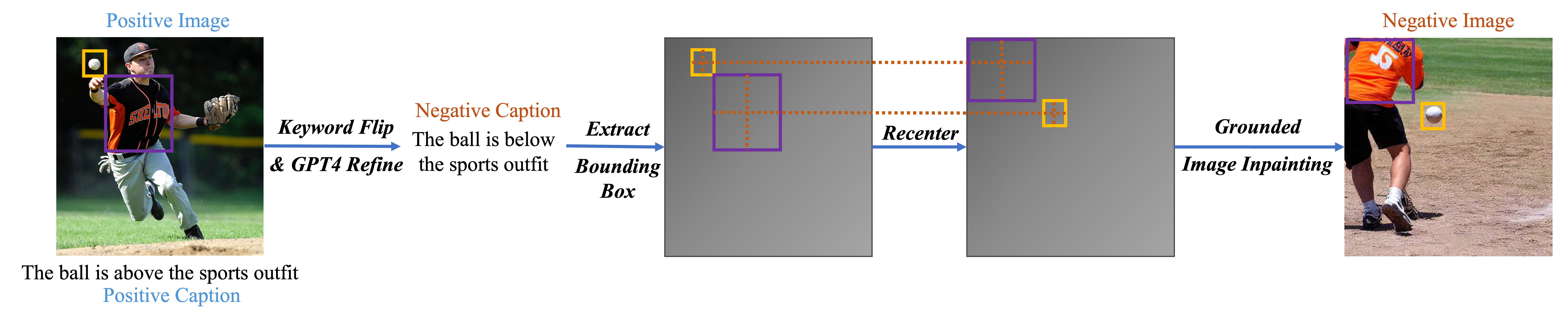
for above/below, we first manipulate the digit, and then apply grounded image inpainting GLIGEN as the negative image;
- Flickr30k-Counting: we first manipulate the digit, and then apply grounded image inpainting GLIGEN as the negative image;
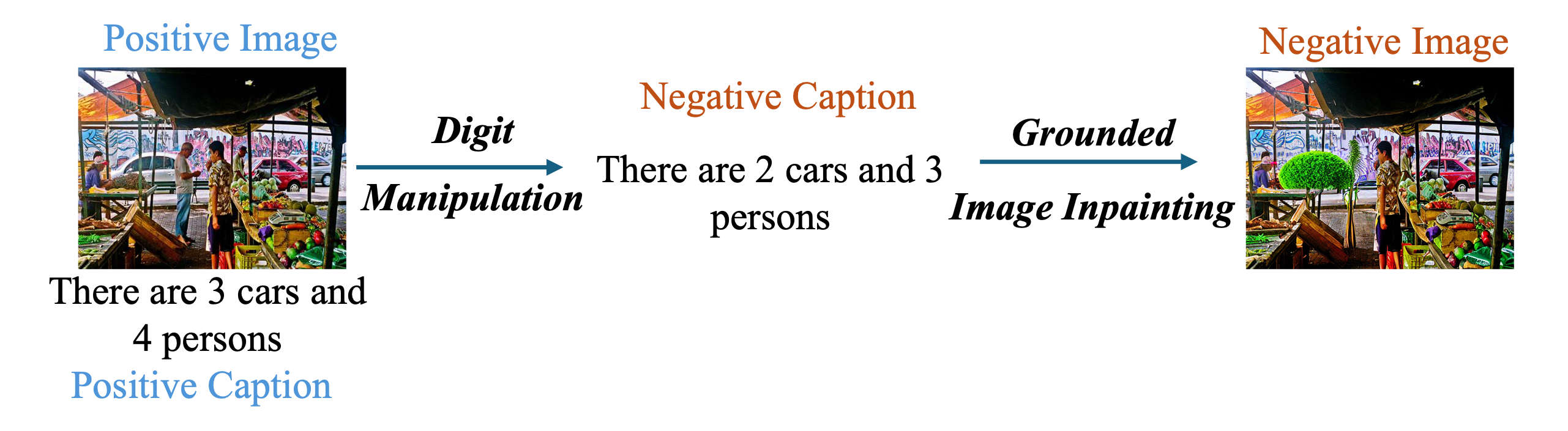
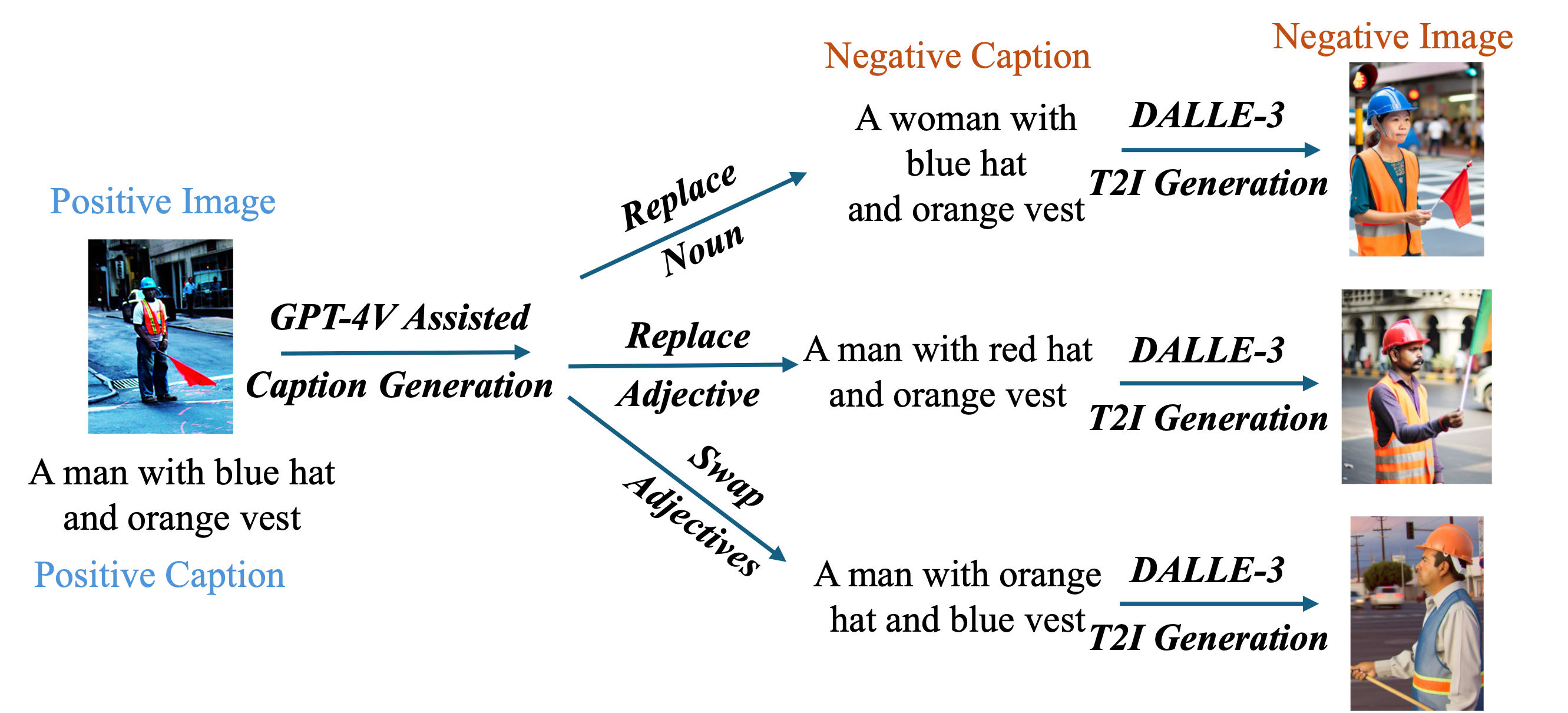
 Finetuning Large Multimodal Models
Finetuning Large Multimodal Models
Fine-tuning different types of large multimodal models with CounterCurate. Our pipeline can enhance both contrastive learning models and generative models by augmenting vanilla image-caption data with curated negative images and captions. Specifically,
- For contrastive learning models like CLIP: our counterfactual image-caption pairs provide auxiliary contrastive loss, where positive contrastive units in the similarity matrix are painted as blue/red and negative ones are painted as white.
- For generative learning models like LLaVA: our counterfactual image-caption pairs can be naturally integrated into the original next-token prediction loss in text generations.
 Performance
Performance
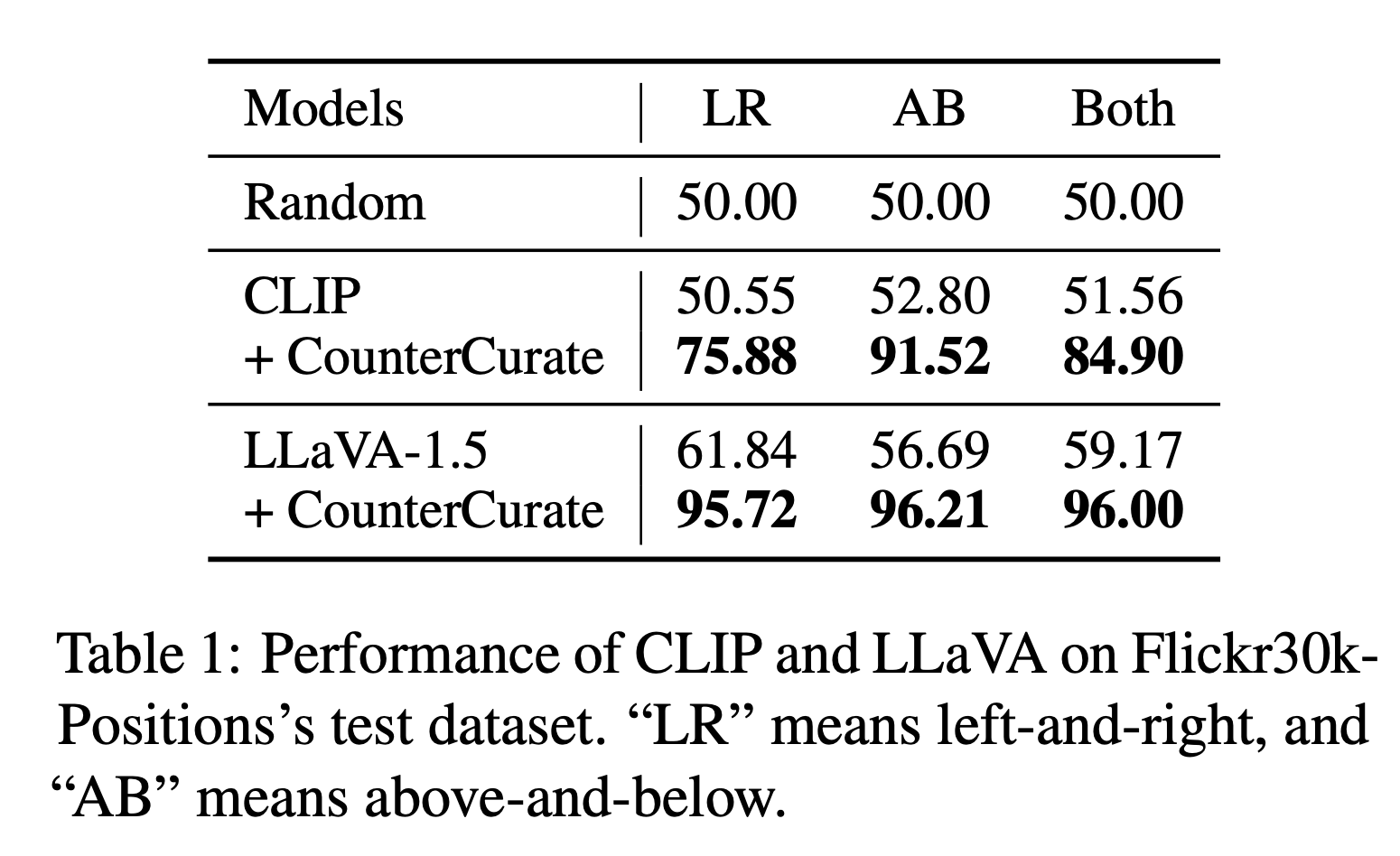
 Positional Understanding: CounterCurate achieves significant performance gain
Positional Understanding: CounterCurate achieves significant performance gain
LMMs are indeed largely oblivious to the objects’ positioning in the image, which is especially manifested in the vanilla CLIP’s performance, which is only marginally better than random guessing. Vanilla LLaVA-1.5 shows slightly better performance.
After fine-tuning with the training split of Flickr30k-Positions, both models perform significantly better across all subsets. Specifically, for the mixed case, CLIP improves by 33%, and LLaVA achieves a high accuracy of 96%. These results demonstrate that CounterCurate is highly effective across different kinds of multimodal models.
 Object Counting: CounterCurate improves the object counting capability
Object Counting: CounterCurate improves the object counting capability
As CLIP performs slightly better than random guessing, it is surprising that LLaVA-1.5 performs worse than random.
Fine-tuning with Flickr30k-Counting improves both models’ counting capability. This shows the effectiveness of using GLIGEN-generated negative images in Coun- terCurate to tackle the problem of counting.

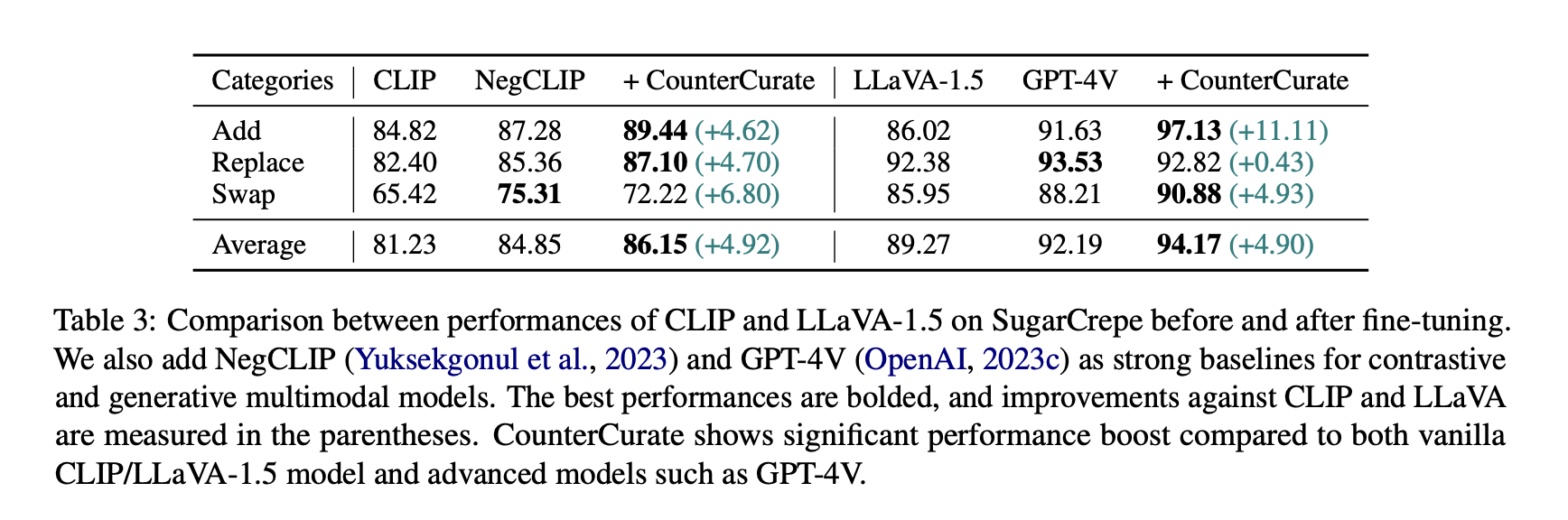
Semantic Compositional
Reasoning: CounterCurate outperforms GPT-4V on SugarCrepe
Evaluating on SugarCrepe, we observe significant improvements for both CLIP and LLaVA-1.5, both on average and categorically. For example, CounterCurate fine-tuned CLIP model surpasses NegCLIP on average. It is also surprising that our fine-tuned model outperforms the SOTA LMM GPT-4V both on average and in two categories, the most significant boost over the “add” category.
BibTeX
@article{zhang2024countercurate,
title={CounterCurate: Enhancing Physical and Semantic Visio-Linguistic Compositional Reasoning via Counterfactual Examples},
author={Zhang, Jianrui and Cai, Mu and Xie, Tengyang and Lee, Yong Jae},
journal={Findings of the Association for Computational Linguistics: ACL 2024},
year={2024}
}
Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
Related Links: [CLIP] [LLaVA] [Instruction Tuning with GPT-4]